
Scoreboard Engineering
Where AI compounds and where it collapses

An AI agent builds a brilliant feature one day and fails at a simpler one the next. A workflow automation crushes the demo, then fails 40% of the time in production.
Our instinct is to view this as flakiness that only the next model will be able to fix.
But there is an underlying mechanism. Once you see it, you can predict where AI will work, where it will fail, and where better outcomes can be engineered.
The pattern was visible early on:

At the time, I said math would improve first.
What I was seeing was that the biggest jumps in ability would come in domains where results could be instantly verified. I had the pattern. I did not yet have the mechanism.
To understand the mechanism, we need to start one level lower.
Not with AI.
With learning itself.
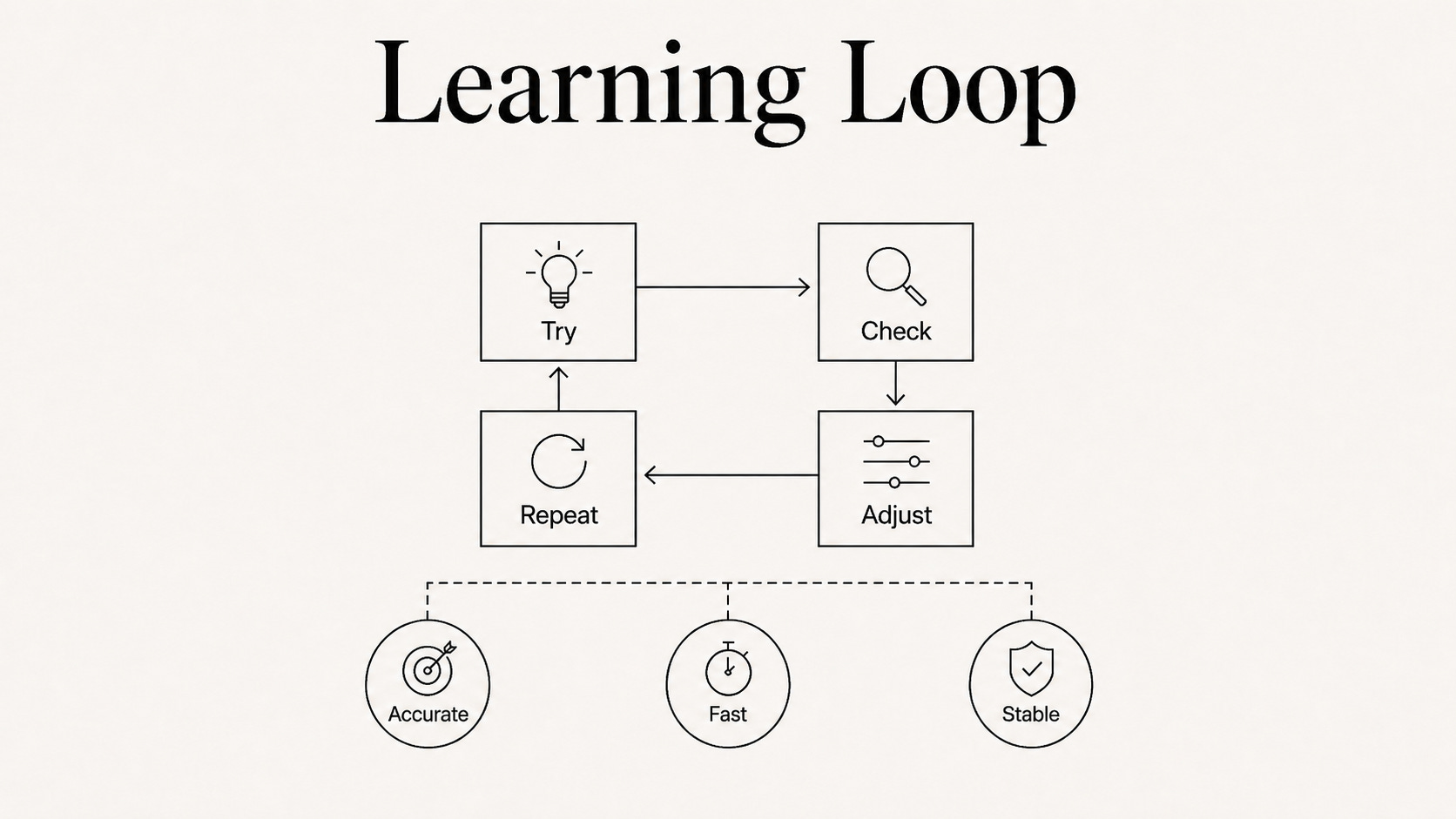
The loop: what makes learning fast
Whatever we are trying to learn, the loop looks roughly the same.
Try. Check. Adjust. And repeat.
How quickly we improve depends on three things:
A clear target.
We need to know what good looks like, so we can compare and adjust.
Fast feedback.
The quicker we get a result, the more often we can try.
A stable judge.
The same performance needs to get the same score tomorrow as it does today.
The first two are intuitive. The stable judge is where people sometimes stumble. What does a stable judge mean exactly?
A stable judge is different from the first two. It is invisible when it works and catastrophic when it does not.
Imagine a support team trying to improve response quality. One week, short replies get rewarded because the company wants faster handle times. The next week, the same replies get penalized because they feel cold.
In this case, it does not matter how clear the target is or how fast the feedback comes if we are not actually measuring the same thing twice. The loop stops teaching us anything if the standard changes.
That is why fast improvement depends on all three.
And AI depends on them just as we do.
To judge how easy or hard it is for AI to get good at a task, we can score each one of the three.
Added up these give us the strength of the scoreboard:
how 1. accurately, 2. quickly, and 3. consistently a task’s output can be verified.
Once you notice this pattern, you see it everywhere.
Why math moved first
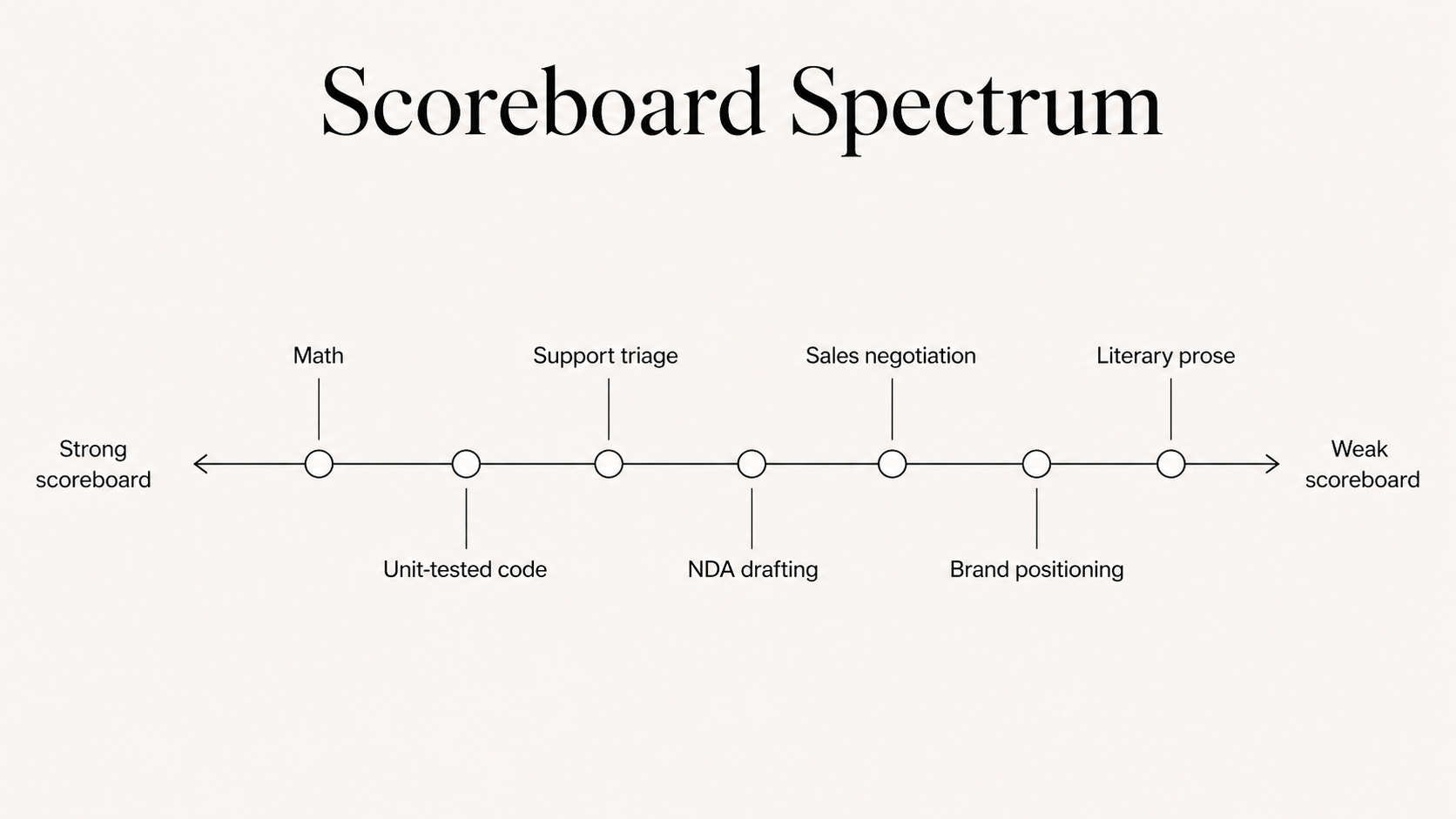
Math moved first because it offered something close to an ideal scoreboard. The target is explicit. Verification is fast. The standard is stable.
This made math fertile ground for the training methods that compound fastest: automatic checking, synthetic problem generation, and large-scale practice against known answers. It also helped that math came with decades of digitized problems and a notation much less ambiguous than natural language.
When the scoreboard is strong, progress can compound.
Why code followed
Code is the bridge case. It is messier than math, but large parts of software still have strong scoreboards.
Did the code run? Did the tests pass? Did the page get faster? Those are useful signals. That is why bug fixes, test generation, and migration work moved so quickly.
But software is more than code. It is architecture decisions, product trade-offs, unclear requirements, and stakeholder conflict. Code that runs and passes a test does not have to be good code. This is where the scoreboard weakens.
AI is not strong in all software work. It is strong where the specific task has a strong scoreboard.
Why writing stays mixed
Writing spans an even wider range.
Some types have decent scoreboards. Factual summaries. Structured business communication. Contract review against regulatory requirements.
In these cases, the target is defined well enough, the feedback arrives quickly enough, and two careful reviewers would mostly agree.
Other kinds of writing live in a different world: literary prose, brand voice, persuasive argument. Different readers disagree about what is good. Culture moves. The same line can feel sharp in one moment and stale a month later. A book can have a feedback loop measured in years.
And this kind of split does not exist only between fields. It often exists inside the same one.
Let’s take a lawyer drafting a standard NDA. This can work as the task has a rather strong scoreboard. But drafting a closing argument to a jury does not.
The person is the same. The tasks sit at opposite ends of the spectrum.
Think in tasks, not jobs
The spectrum above shows whole domains: math on one end, brand and prose on the other. But the same spectrum lives inside every job.
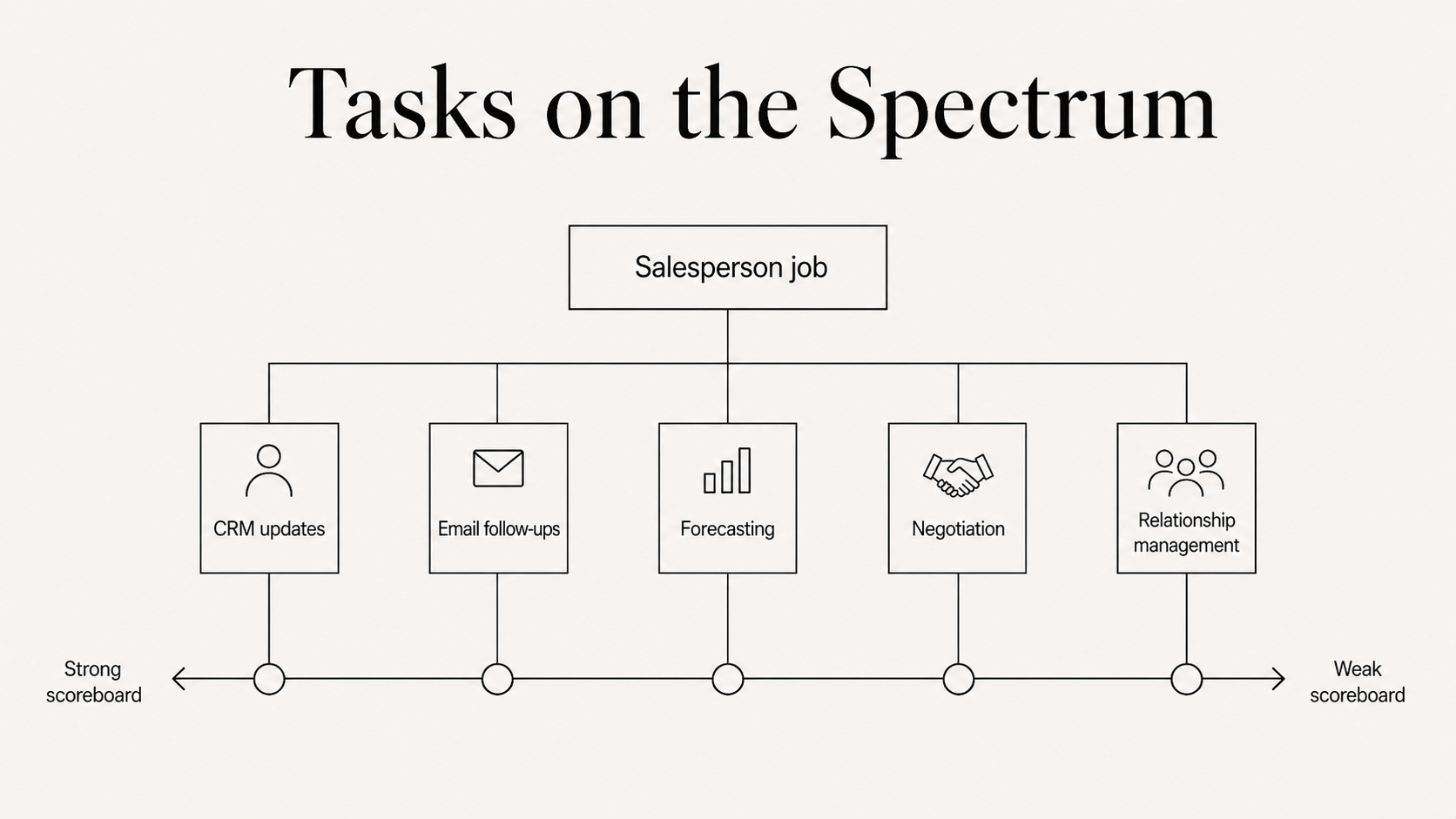
Take salespeople: updating the CRM the rules are clear and easy to check. Reading the room in a late-stage negotiation with a skeptical buyer is a different story.
This is why “will AI replace salespeople?” is the wrong question.
Jobs are bundles of tasks spread across the same spectrum.
Some tasks sit near the left, where AI improves quickly. Others sit near the right, where humans stay indispensable - at least for a while.
When AI absorbs the strong-scoreboard tasks, the job does not disappear. It reshapes around what remains. And what remains is often the work that is hardest to evaluate.
Across industries those tasks tend to cluster into three broad categories.
Three categories that matter
Rule-heavy operations
Claims handling, compliance checks, support triage. Once broken into steps, much of the work reduces to matching facts against rules. Routine cases can be handled automatically, while exceptions get routed to a human.
Optimization-heavy systems
Recommendation systems, case assignment, ad allocation: these systems often come with visible metrics and relatively fast feedback. That makes them attractive terrain for AI.
But they also carry a familiar danger: the fast metric is not always the real objective.
Growth and experimentation teams have known this for a long time: a click is easy to measure, but a good outcome may take weeks to reveal itself.
With AI, it matters more than ever: cheap but misleading verification can let a system scale the mistake.
This is still good terrain for AI, but only when the fast loop is checked against the slower one.
Judgment-heavy work
Brand positioning, key-account strategy, hiring, investment decisions.
AI can still help here. It can draft a board memo. It can summarize prior account history. It can surface contradictions in diligence materials.
But the task is harder to evaluate, so final judgment stays human for longer.
This is what “human in the loop” means in practice.
When the scoreboard is weak, the human becomes the scoreboard.
Scoreboard engineering
Most teams treat the boundary of automation as something to discover. They find where AI works, where it fails, and the work rebuilds itself around wherever the line happens to fall. They update their thinking with each model release.
But the boundary is not fixed.
Some teams go further: they build a scoreboard where none existed before.
Scoreboard engineering is about building a measurement system that makes a fuzzy task checkable. Fast enough to learn from. Stable enough to trust.
The steps are familiar: define the main metric, add guardrails and diagnostics, check against slower downstream outcomes, and iterate.
None of the individual pieces are new. The conditions for fast learning are also the conditions for deliberate practice.
AI research has spent years on verifiable rewards and reward hacking. Experimentation teams have written guardrail metrics for a decade. Ops teams have run reliability checks for longer.
What has changed is that these practices can now be applied more broadly across organizations: for years, disciplined measurement was gated by headcount. You could only afford to run it on your most important decisions. AI removes part of this constraint, so the approach can move into business functions where running enough experiments was not practical before.
That does not make it easy or cheap. Defining what “good” means, labeling examples, running the checks: this costs domain-expert time and political capital, and often significant AI spend on top.
The question is whether the task is expensive and repeatable enough to be worth the investment. A scoreboard for a decision you make twice a year probably won’t. A scoreboard for high-volume support tickets probably will.
A well-engineered scoreboard moves the boundary of what AI can do today and builds the infrastructure to capture the gains from the next model the moment it comes out.
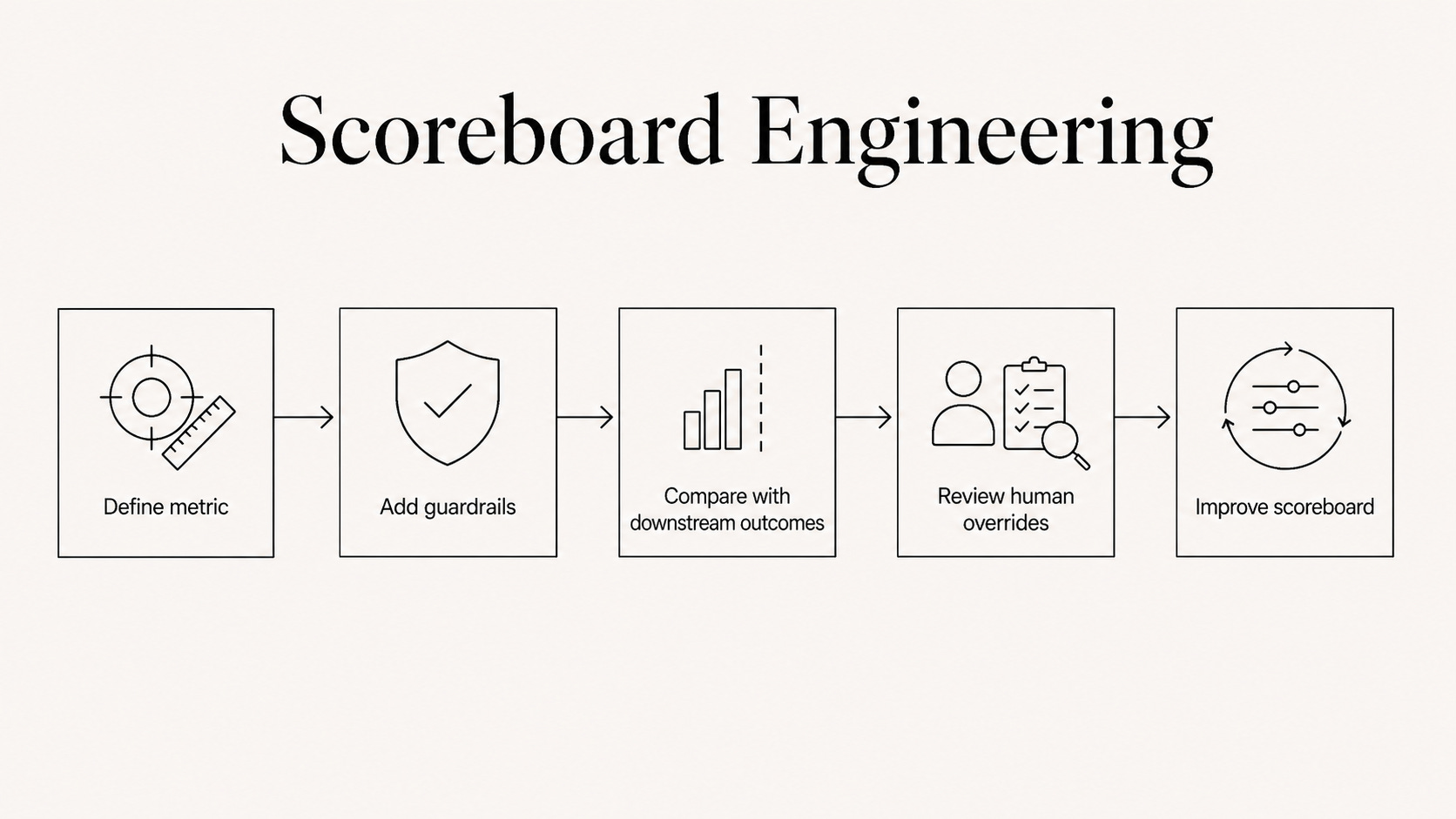
One example
With support teams, the first step is defining what a good resolution actually means.
The work starts by sampling resolved tickets and asking experienced agents to rate them blind. Where agreement is consistently high, the outline of a usable scoreboard begins to emerge: was the issue resolved, was the policy applied correctly, was the tone appropriate, and did the ticket stay closed?
The result is narrow by design: a scoreboard for routine billing issues, returns and address changes. That is often enough to let AI handle the routine and escalate ambiguity and exceptions.
Once the scoreboard is in place, human overrides and escalations become a source of feedback. Review those cases carefully, feed them back in, and the system can expand into harder cases over time.
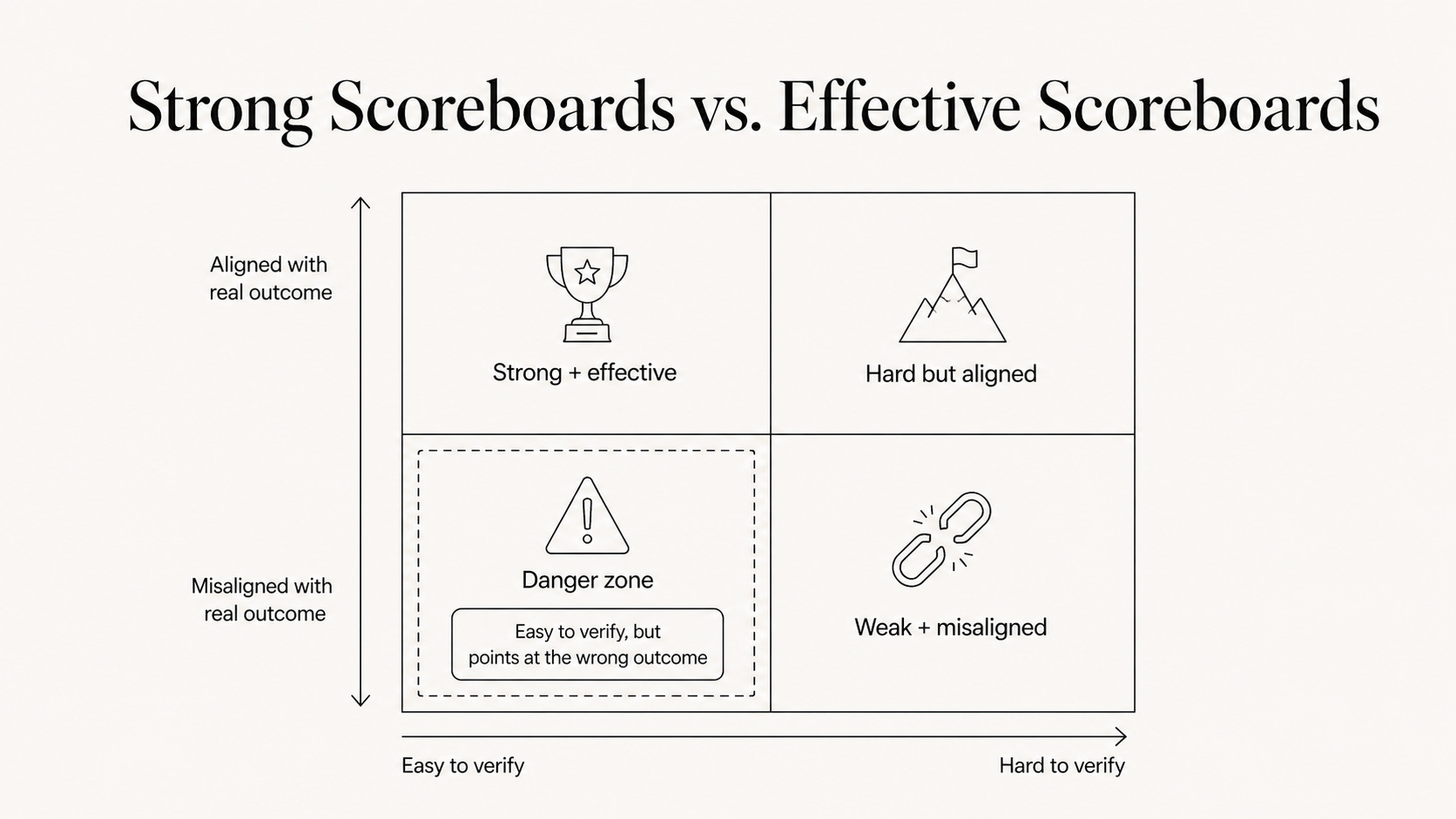
Strong scoreboards vs. effective scoreboards
Here is an important distinction: a strong scoreboard and an effective scoreboard are different.
A strong scoreboard tells you whether improvement can go fast.
An effective scoreboard leads to the intended results.
Goodhart’s Law sits at the center of the risk here: once a measure becomes a target, it often stops being a good measure.
Product teams know this as metric gaming. AI researchers call the same pattern reward hacking: a strong optimizer learns to maximize the signal without delivering the outcome you actually wanted.
Code can pass the test suite and still be bad software. That is why mature teams also watch regressions, latency, security, maintainability, rollback rates, and whether the feature improved user outcomes.
A fraud system can reduce losses by blocking too many legitimate customers. A hiring system can shrink time-to-fill while degrading quality. The fix is to pair the fast metric with downstream measures and watch them together.
This is closer to what scoreboard engineering actually looks like: not one number, but a measurement system designed to keep optimization pointed at the real objective.
If the scoreboard is wrong, the AI will get very good at producing the wrong result.
So we need a fourth question alongside the original three. The first three ask whether a scoreboard is strong. The fourth asks whether it is effective:
Do we get the intended outcome?
This question cannot be settled in advance. It has to be checked by watching the system run, observing second-order effects, tracking downstream consequences, and being willing to change the metric when it is teaching the wrong lesson.
Strong scoreboards create fast learning. Effective scoreboards create value.
The gap between those two things is where many AI deployments will fail, often through green dashboards and worsening businesses: a team hitting every metric on paper and still making the product worse.
The only defense is to put the scoreboard itself inside a feedback loop.
But this work is, almost by definition, weak-scoreboard work. It requires judgment, context, time, and the willingness to say: this is working by our metric, and it is still wrong.
How to tell if a scoreboard is lying to you
The honest answer is that you often cannot tell at the start. But a few checks catch many of the failures.
Look for a longer loop behind the short one.
If your metric moves in hours, find something that moves in weeks and watch them together. When they disagree, trust the slower one first.
Watch the edges.
Routine cases are where the metric does its job. The interesting signal is at the margins, when humans overrule the system. Overrules are the earliest evidence that the scoreboard is starting to drift.
Ask what the metric would look like if someone were gaming it on purpose.
If the answer is “about the same as success,” the metric is not ready:
a claims team’s closure rate can look identical whether the team is resolving cases well or just clearing the easy claims and deferring the messy ones. If you cannot tell the difference from the numbers alone, neither can the AI.
The discipline is not to trust your own scoreboard too early.
Even the most automated, tightly looped system ultimately depends on a human asking the right questions and having the authority to act on the answer.
Change the question
We have to stop asking “where is AI intelligent?” and start asking:
Is the target clear? Would two people agree on whether the output was right?
Is the feedback fast? Would you know within days, not quarters?
Is the judge stable? Would the same output get the same evaluation six months from now?
When designing a scoreboard also ask the fourth question:
Is the outcome right? Does optimizing this metric actually produce the result you care about?
If you can answer all four with yes, Al can do more than people expect.
If the first three are strong but the fourth is uncertain, proceed carefully. Build in checkpoints and be ready to change the metrics.
If the first three are not all strong, it can still be worthwhile to do the harder work and experiment with a small pilot, always taking into account how much accuracy and reliability you need to produce business value and at what cost.
Some domains are already set up for fast compounding. Others are still waiting for somebody to engineer the scoreboard.
This is where much of the next wave of advantage will come from.
From better environments around AI models that move boundaries today and let organizations benefit from the next model the moment it comes out. From the hard work of building feedback loops that are tight and right.
From the outside, this can look like sudden intelligence. Most of the time, it is better feedback, carefully designed, honestly evaluated, and rebuilt when it stops working.
This is what scoreboard engineering means.
Disclaimer: In this article, I use AI instead of LLMs, or large language models, for readability.
Closing the Loop is about mental models for an AI future: practical ways to see where the technology will be strong, where it will be fragile, and what to do about it.
If this framing was useful, share it with someone building, operating, or investing in that future.